



严格意义上HGX里面有8个GPU,每个GPU为一个Module 这个才叫做模组,HGX 其实是由8个GPU 模组和4个NVLInk Switch组成,下图所示,就是每个上图的SINK 下面的GPU模组。

放大的图:
严格意义的模组 中间就是H100/A100这种GPU,通过SXM SOCKET 接口和GPU主板连接。

然后下图是8个GPU 模组通过4 个NVLINK SWITCH 连接,组成一个8GPU的“大号”GPU。

在H100 SXM GPU上加装散热器后,便构成了HGX,这是由英伟达设计的一种配置,作为直接供应给服务器制造商的“最 小单元”。需要注意的是,HGX本身并不能单独运行,因为它本质上是一个“大型逻辑GPU”,必须与服务器平台(即服务器主体)结合使用,才能构成一个完整的GPU服务器。这种完整的服务器便是NVIDIA DGX,一款由英伟达品牌提供的GPU服务器。除了核心的HGX模块之外,DGX还配备了服务器所需的其他组件,如机箱、主板、电源、CPU、内存、存储设备及网络接口卡等。 尽管在功能和结构上,NVIDIA DGX与其他服务器制造商基于HGX模块构建的GPU服务器没有显 著差异,但由于其高昂的价格以及可能与合作伙伴产生市场竞争的考虑,NVIDIA通常不会广泛推广DGX产品,除非是针对特定客户群体。事实上,NVIDIA DGX更多地出现在每年GTC大会等场合,用于展示 新的GPU技术,例如直接赠送给像ChatGPT实验室这样的研究机构或在发布会上向客户展示。这一策略既体现了NVIDIA希望通过DGX来吸引关注和宣传新技术的意图,同时也避免了与生态系统中的合作伙伴发生直接竞争。
因此,从某种程度上讲,DGX可以被视为一种“概念车型”的存在,主要用于技术和市场的展示目的,而非大规模商业销售。出于对合作伙伴关系的维护,NVIDIA在多数情况下并不在美国及其他地区广泛销售DGX。鉴于此,为了更贴合实际应用情况,我们将以超微公司的一款SYS-821GE-TNHR AI服务器为例进行介绍,这款服务器在设计和性能上与DGX有着相似之处。




接下来就是这个系统贵的部分HGX的俯视图, 主要由8个H100 和4个NVLINK Switch组成,号称占到整个系统的90%,这个就是Intel 的股票为啥腰斩,而NVIDIA的股票狂涨的原因。AIGC这波操作,Intel几乎没有赚到多少钱 ,一个系统就卖2个CPU 估计1%都不到,但是8个GPU占到整个系统的90%成本。

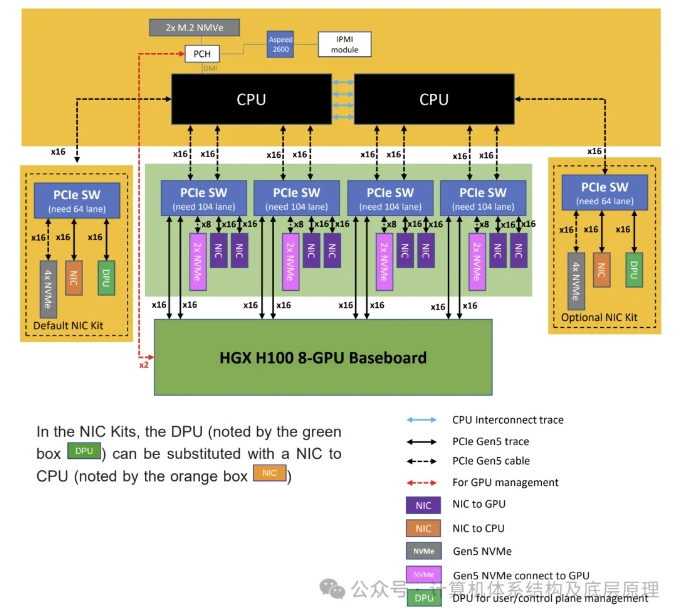
系统架构图:
观看了整个机器的外部和内部结构,在这个基础上理解系统架构图就比较容易
1. 上面的motherboard 主板,主板主要由CPU 内存组成,两个CPU SOCKET 通过4个UPI LINK连接,CPU通过DMI连接PCH (南桥,Intel 又叫 Platform Controller Hub) 再连接BMC和2个M.2 Nvme 应该装OS使用,2个M.2 NVMe 可以组成RAID 1.
2. 中间底部的表示的为上面介绍的PCIe Switch Board, 每个CPU因为是Intel 第4代/5代 CPU 可以支持80个PCIe Lane ,所以总共可以支持160Lane,连接到6个PCIe Switch ,其中4个PCIe Switch 是用来和HGX 上的GPU通信的,每个PCIe SW上端USP(Upstream Port) 32 PCIe Lane ,下端DSP(Downstream Port) 72 PCIe Lane 总共104 Lane。DSP 下端每个PCIe Switch可以接两张x16网卡,总共8张网卡,假设每个网卡可以提供200Gb/s的带宽, 则可以通过这些网卡实现1.6T Gb/s的跨Node GPU-GPU带宽,使用GPUDirect RDMA 可以实现GPU跨Node 的直接连接而无需CPU介入 ,从而实现Server 和 Server之间的8 GPU通讯,把若干各8 GPU组网连接在一起。这对大模型训练特别有用,大模型训练里面一个概念 模型并行,模型并行(Model Parallel, MP)通常是指在多个计算节点上分布式地训练一个大型的神经网络模型,其中每个节点负责模型的一部分。这种方法主要用于解决单个计算节点无法容纳整个模型的情况。模型并行可以进一步细分为几种策略,PP和TP。每个PCIe Switch DSP里面还有另外两个x16 PCIe lane用来接入GPU到HGX,这个是CPU-GPU的通信,主要是CPU对GPU进行控制流的操作,类似大模型的训练都在HGX 里面的GPU执行了,但是开始进行初始化和一些数据准备操作以及命令配置等是由CPU 代表操作系统模型框架来下发到GPU的,所以还是需要通信的,只不过这个通信没有GPU-GPU之前的数据量那么大。每个PCIe SW 还有一个8lane 是留给2 x NVMe SSD 使用,总共支持64lane ,8个NVMe SSD 用来进行本地存储。
3. 两侧各可以配置一个PCIe Switch这两个一个是default 一个是可选,用来做CPU 的网络通信使用,即这两个CPU和其他的Server 之间的通信,可以配置为NIC 或者DPU 做NVMe RoceV2 协议卸载,可以实现GDS和存算分离的存储集群通过 GDS( GPUDriect Stroage )连接。另外两个x16的PCIE 再可以接8个NVme 加上PCIe Switch board 的8个系统总共支持18个NVME U.2.
来源:



