



1875 个主机(每个主机配备 8 块 GPU 和 9 块网卡)使用阿里云的高性能网络,通过以太网进行通信。
阿里云工程师兼研究员翟恩南通过 GitHub 分享了其研究论文,介绍了阿里云用于大语言模型(LLM)训练的数据中心的设计。
这份 PDF 文件名为《阿里巴巴 HPN:用于大语言模型训练的数据中心网络》,概述了阿里巴巴如何使用以太网让 15000 块 GPU 得以相互通信。

一般的云计算生成一致的小数据流,速度低于 10 Gbps。另一方面,LLM 训练生成的周期性数据突发可以达到 400 Gbps。
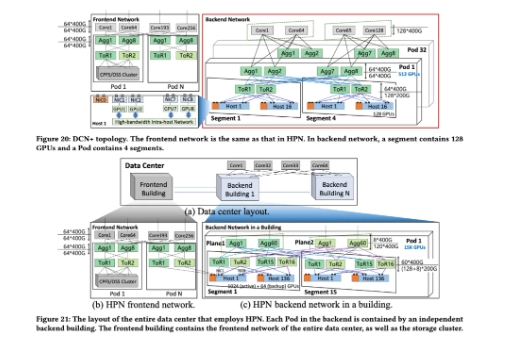
据论文声称:“LLM训练的这一特性使得传统数据中心常用的负载均衡方案等价多路径路由(ECMP)容易出现哈希极化,从而导致流量分布不均等问题。”为了避免这种情况,翟恩南及其团队开发了高性能网络(HPN),HPN 使用了“两层双平面架构”,这种架构减少了可能发生 ECMP 的数量,同时让系统可以“精 确地选择能够容纳大象流(elephant flow)的网络路径”。
HPN 还使用了双架顶式(ToR)交换机,这使得它们可以相互备份。这些交换机对 LLM 训练而言是最常见的单点故障,需要 GPU 同步完成迭代。
每个主机 8 块 GPU,每个数据中心 1875 个主机
阿里云将其数据中心划分为多个主机,每个主机又配备 8 块 GPU。每块 GPU 都有搭载两个端口的网卡,每个 GPU-网卡系统称为“rail”。主机还得到一块额外的网卡连接到后端网络。然后,每个 rail 连接到两个不同的 ToR 交换机,确保即使一个交换机出现故障,整个主机也不会受到影响。
尽管阿里云丢弃了用于主机间通信的 NVlink,但仍然使用英伟达的专有技术用于主机内网络,因为主机内 GPU 之间的通信需要更多的带宽。
然而,由于 rail 之间的通信速度慢得多,每个主机“专用的 400 Gbps RDMA 网络吞吐量,导致总带宽为 3.2 Tbps”足以确保 PCIe Gen5x16 显卡的带宽最 大化。
阿里云还使用了 51.2 Tbps 的以太网单芯片 ToR 交换机,因为多芯片解决方案更容易不稳定,故障率是单芯片交换机的四倍。
然而,这些交换机运行时散热量大,市面上没有现成的散热器可以阻止它们因过热而关闭。因此,阿里云想出了一个新颖的解决方案,即设计一个均热板散热器,中心有更多的小柱子,大大提高传导热能的效率。
翟恩南及其团队将于今年 8 月在澳大利亚悉尼举行的数据通信特别兴趣小组(SIGCOMM)大会上展示其研究成果。包括 AMD、英特尔、谷歌和微软在内的多家公司都会对这个项目感兴趣,主要是由于它们已联合起来创建了 Ultra Accelerator Link——这是一种开放标准的互连技术,旨在与 NVlink 竞争。
阿里云使用 HPN 已有八个多月,这意味着这项技术已经过了尝试和测试。然而,HPN 仍然存在一些缺点,其中最 大的缺点就是其复杂的布线结构。鉴于每个主机有 9 块网卡,每块网卡连接到两只不同的 ToR 交换机,很有可能混淆哪个插孔到哪个端口。尽管如此,这项技术可能比 NVlink 来得实惠,因此任何建立数据中心的机构都可以大幅节省安装成本。
来源:Al头条
